




I. Présentation de Postgres-XL▲
I-A. Vue d'ensemble▲
Postgres-XL est un cluster de bases de données horizontalement extensible. Basé sur PostgreSQL, il est également open source. Le cluster est conçu de manière à gérer différents types de requêtes, que ce soit des charges opérationnelles ou une analyse décisionnelle nécessitant de gros traitements parallèles.
La particularité de Postgres-XL face à d'autres systèmes assurant la scalabilité horizontale est la conservation de la règle ACID grâce à des composants spécialisés ainsi qu'à un système de contrôle de versions. L'utilisateur garde ainsi une vue consistante à tout moment sur les données distribuées à travers les nœuds comme s'il s'agissait d'une seule base.
Postgres-XL permet la réplication des données à travers les nœuds ce qui satisfait une scalabilité en lecture (les lectures de données peuvent être distribuées sur les nœuds et s'exécuter en parallèle accélérant la latence globale). Les données répliquées sont le plus souvent les tables les plus statiques, car elles doivent être disponibles sur tous les nœuds. Cette disponibilité permet d'opérer des jointures localement au niveau de chaque nœud.
Le système permet aussi un autre type de distribution : par partitionnement. Les données sont partagées entre les nœuds selon une stratégie particulière. Ainsi chaque nœud disposera d'une partie ou fragment de données. La technique avantage les traitements en parallèle sur des fragments de données. Elle satisfait la scalabilité en écriture (les écritures peuvent se faire en parallèle). C'est ce type de distribution par partitionnement que nous étudierons dans les expérimentations présentées dans ce tutoriel.
I-B. Composants▲
La figure ci-dessous explique l'architecture distribuée de la solution fournie par Postgres-XL. Nous retrouvons trois types de composants.
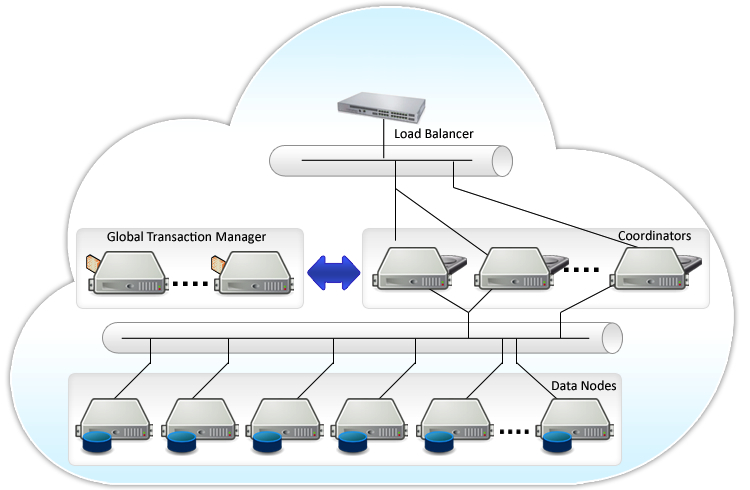
I-B-1. Gestionnaire GTM (Global Transaction Manager)▲
Le composant Gestionnaire Global des Transactions (GTM) assure la cohérence des données au sein du cluster et gère les transactions ainsi que le versionnement des tables et enregistrements. Le GTM peut être agrémenté d'un ou plusieurs standby qui reprennent le contrôle en cas de pannes.
I-B-2. Coordinateur (Coordinator)▲
Le Coordinateur (Coordinator) gère tout ce qui est sessions utilisateur et interagit avec le GTM et les nœuds de données. Il réceptionne les requêtes, initie les plans d'exécution et les distribue aux nœuds de données. Plusieurs coordinateurs peuvent être définis afin de répartir la charge.
I-B-3. Nœud de données (Data node)▲
Le Nœud de Données (Data Node) stocke les données en l'occurrence. Ils exécutent également les plans de requêtes envoyés par les coordinateurs.
I-B-4. Nœud de données esclave (Slave node)▲
Le Nœud de Données esclave (Slave Data Node) sert à gérer la réplication de nœuds de données. Si ce dernier est inaccessible, le nœud de données esclave associé prendra sa place. Le maintien des données à jour entre le nœud de données et le nœud de données esclave est fait de manière synchrone. Toutes données insérées dans le nœud de données sont répliquées à l'identique vers l'esclave.
I-C. Cluster▲
Il faut donc trois nœuds pour créer un cluster Postgres-XL même si dans les faits un seul nœud pourrait supporter les trois types de composants. Toutefois ce scénario enlève toute la logique de distribution fournie par Postgres-XLPostgres-XL. Dans le cas normal, un cluster minimaliste comporterait un nœud pour Gestionnaire GTM (Global Transaction Manager), un nœud pour le Coordinateur et deux nœuds de données.
II. Prérequis matériels et logiciels▲
Les prérequis matériels et logiciels pour reproduire les expérimentations de ce tutoriel sont les suivants :
- disposer de cinq machines (virtuelles ou physiques) ;
- Linux Ubuntu ou Debian ;
- Postgres-XL ;
- des connaissances en commandes bash.
III. Architecture et protocole d'expérimentation▲
Nous allons installer un cluster Postgres-XL qui sera composé de cinq nœuds au maximum. Chaque nœud est une machine virtuelle gérée par un serveur de virtualisation Xen.
Les caractéristiques du serveur sont les suivantes :
- processeur : Intel XEON E5-2630 V3 @2.40GHz. 16 Logical CPU ;
- capacité mémoire : 128 Go ;
- capacité disque dur : 4 To ;
- système d'exploitation : Linux sur Xen Server 6.5.0.
Les caractéristiques de chaque machine virtuelle sont les suivantes :
- processeur : 4vCPU dont 4 sockets avec 1 core par socket ;
- capacité mémoire : 8 Go ;
- capacité disque dur : 100 Go ;
- système d'exploitation : Ubuntu 16.04 LT serveur.
À titre indicatif nous donnons les adresses IP que nous avons utilisées. Celles-ci peuvent être modifiées si vous souhaitez expérimenter sur votre cluster. Voici la décomposition que nous avons retenue pour cette expérimentation.
-
Nœud 1 :
- rôle : GTM (Global Transaction Manager) ;
- host : gtm ;
- IP : xxx.yyy.zzz.213.
-
Nœud 2 :
- rôle : coordinateur ;
- host : coord ;
- IP : xxx.yyy.zzz.214.
-
Nœud 3 :
- Rôle : Nœud de données
- Host : dn1
- IP : xxx.yyy.zzz.215
-
Nœud 4 :
- rôle : nœud de données ;
- host : dn2 ;
- IP : xxx.yyy.zzz.216.
-
Nœud 5 :
- rôle : esclave d'un nœud de données (nœud 3) ;
- host : dn2 ;
- IP : xxx.yyy.zzz.217.
Dans la suite du tutoriel, nous avons volontairement détaillé toutes les phases de la configuration et de l'installation de manière manuelle. Lors de nos expérimentations, nous avons préparé une machine virtuelle de référence que nous avons dupliquée autant de fois que de nœuds présents et nous avons configuré le premier nœud avec l'outil pgxc_ctl. Des scripts d'installation ont été utilisés pour accélérer l'installation. Nous les présentons ci-dessous :
- 01_installallnodes.sh : script pour l'installation pour tous les nœuds ;
- 02_configureallnodes.sh : script pour la configuration ;
- 03_installnode1gtm.sh : script pour le nœud Global Transaction Manager ;
- pgxc_ctl.conf : fichier de configuration pour le nœud Global Transaction Manager.
Tous les scripts sont disponibles sur le dépôt Github suivant : https://github.com/mickaelbaron/postgresxl-scripts
IV. Installation et configuration du cluster▲
IV-A. Téléchargement▲
Sur chaque nœud
- En mode super utilisateur Linux (via sudo), créer un nouvel utilisateur postgres qui sera l'administrateur du cluster. Pour simplifier l'installation, nous choisirons le mot de passe postgres.
2.
$ sudo useradd postgres --shell /bin/bash --home /home/postgres --create-home
$ echo -e 'postgres\npostgres\n' | sudo passwd postgres
- Ajouter l'utilisateur postgres dans la liste des sudoers.
2.
$ sudo adduser postgres sudo
$ sudo chsh -s /bin/bash postgres
- Dans la suite du tutoriel, vous vous connecterez et vous utiliserez par défaut l'utilisateur postgres.
- Exécuter les commandes suivantes afin de mettre à jour le système et d'installer les dépendances nécessaires.
2.
3.
$ sudo apt-get update -y
$ sudo apt-get install software-properties-common python-software-properties -y
$ sudo apt-get install wget zip gcc libreadline6 libreadline6-dev zlib1g-dev build-essential flex -y
- Télécharger dans le répertoire home de l'utilisateur postgres le code source depuis la plateforme SourceForge.
2.
$ cd /home/postgres
$ sudo wget https://sourceforge.net/projects/postgres-xl/files/latest/download
IV-B. Installation▲
Sur chaque nœud
- Se connecter sur chaque machine en tant qu'utilisateur postgres (le mot de passe configuré est postgres) et compiler le source.
2.
3.
4.
5.
$ cd /home/postgres
$ tar xfv download
$ cd /home/postgres/postgres-xl-9.5r1.4/
$ ./configure
$ make
- Installer Postgres-XL.
2.
$ cd /home/postgres/postgres-xl-9.5r1.4/
$ sudo make install
Sur le nœud 1 uniquement (GTM)
- Compiler et installer l'utilitaire pgxc_ctl en exécutant les lignes de commande suivantes.
2.
$ cd /home/postgres/postgres-xl-9.5r1.4/contrib/pgxc_ctl
$ make
- En tant que super utilisateur (sudo), installer l'utilitaire.
2.
$ cd /home/postgres/postgres-xl-9.5r1.4/contrib/pgxc_ctl
$ sudo make install
IV-C. Configuration▲
IV-C-1. Configuration générale▲
Sur toutes les machines
- Désactiver le firewall.
$ sudo ufw disable
- Modifier la variable d'environnement $PATH en éditant le fichier /etc/environment.
$ sudo vim /etc/environment
- Ajouter /usr/local/pgsql/bin: au début de la variable PATH.
PATH='/usr/local/pgsql/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games'
IV-C-2. Configuration ssh▲
Afin que les nœuds du cluster communiquent, il faudra supprimer l'authentification ssh par mot de passe. Pour cela, on va générer une clé RSA sur le nœud 1 qu'il faudra copier vers les autres nœuds.
Sur le nœud 1 uniquement :
- Créer un dossier .ssh dans le dossier home de l'utilisateur postgres s'il n'existe pas.
2.
$ mkdir ~/.ssh
$ chmod 700 ~/.ssh
- Ensuite, générer une clé RSA sur le nœud 1 et l'enregistrer dans un fichier. Valider pour spécifier ses paramètres :
2.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- Copier la clé RSA ensuite sur chacun des nœuds restants :
2.
3.
4.
$ scp ~/.ssh/authorized_keys postgres@xxx.yyy.zzz.214:~/.ssh/
$ scp ~/.ssh/authorized_keys postgres@xxx.yyy.zzz.215:~/.ssh/
$ scp ~/.ssh/authorized_keys postgres@xxx.yyy.zzz.216:~/.ssh/
$ scp ~/.ssh/authorized_keys postgres@xxx.yyy.zzz.217:~/.ssh/
Sur chaque nœud :
- Exécuter ensuite ces commandes :
2.
$ chmod 700 ~/.ssh
$ chmod 600 ~/.ssh/authorized_keys
IV-C-3. Création d'un cluster de trois nœuds▲
La configuration du cluster est facilitée par l'outil pgxc_ctl à partir du nœud 1. Ce dernier enregistre ses fichiers de configuration par défaut dans /home/postgres/pgxc_ctl.
La configuration passe principalement par le fichier /home/postgres/pgxc_ctl/pgxc_ctl.conf. Les modifications dessus peuvent se faire en éditant le fichier manuellement ou à travers la commande pgxc_ctl.
- Nous allons utiliser cette dernière afin de générer une version standard de ce fichier qu'on personnalisera par la suite.
2.
3.
4.
5.
6.
7.
8.
9.
10.
$ pgxc_ctl
/bin/bash
Installing pgxc_ctl_bash script as /home/postgres/pgxc_ctl/pgxc_ctl_bash.
ERROR: File "/home/postgres/pgxc_ctl/pgxc_ctl.conf" not found or not a regular file. No such file or directory
Installing pgxc_ctl_bash script as /home/postgres/pgxc_ctl/pgxc_ctl_bash.
Reading configuration using /home/postgres/pgxc_ctl/pgxc_ctl_bash --home /home/postgres/pgxc_ctl --configuration /home/postgres/pgxc_ctl/pgxc_ctl.conf
Finished reading configuration.
******** PGXC_CTL START ***************
Current directory: /home/postgres/pgxc_ctl
- Saisir la commande suivante pour recréer un fichier de configuration pgxc_ctl.conf vide. Celui-ci sera créé dans le répertoire /home/postgres/pgxc_ctl.
PGXC prepare config empty
- Éditer le fichier pgxc_ctl.conf généré.
PGXC vim ~/pgxc_ctl/pgxc_ctl.conf
- Modifier les trois champs suivants.
2.
3.
4.
5.
6.
7.
8.
# user and path
pgxcOwner=postgres # L'administrateur du Cluster
# coordinator
coordPgHbaEntries=(xxx.yyy.zzz.0/24) # Configuration du réseau pouvant émettre des requêtes
# datanode
datanodePgHbaEntries=(xxx.yyy.zzz.0/24) # Réseau autorisé à accéder aux noeuds
- La prochaine étape est d'utiliser pgxc_ctl afin d'ajouter les nœuds du cluster. Seuls les paramètres principaux sont spécifiés, c'est-à-dire, le nom du nœud, son adresse, les ports de connexion et le répertoire de travail. Le premier nœud à ajouter sera le nœud gestionnaire (GTM).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
PGXC add gtm master gtm xxx.yyy.zzz.213 20001 /home/postgres/pgxc/gtm
Initialize GTM master
The files belonging to this GTM system will be owned by user "postgres".
This user must also own the server process.
fixing permissions on existing directory /home/postgres/pgxc/gtm ... ok
creating configuration files ... ok
creating control file ... ok
Success.
Done.
Start GTM master
waiting for server to shut down.... done
server stopped
server starting
- Le deuxième nœud à ajouter sera le coordinateur.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
PGXC add coordinator master coord1 xxx.yyy.zzz.214 20004 20010 /home/postgres/pgxc/coord1 none none
Actual Command: ssh postgres@xxx.yyy.zzz.214 "( PGXC_CTL_SILENT=1 initdb -D /home/postgres/pgxc/coord1 --nodename coord1 ) > /tmp/s-virtualmachine10-lias_STDOUT_8445_0 2>&1" < /dev/null > /dev/null 2>&1
Bring remote stdout: scp postgres@xxx.yyy.zzz.214:/tmp/s-virtualmachine10-lias_STDOUT_8445_0 /tmp/STDOUT_8445_1 > /dev/null 2>&1
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "fr_FR.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "french".
...
syncing data to disk ... ok
freezing database template0 ... ok
freezing database template1 ... ok
freezing database postgres ... ok
...
Starting coordinator master coord1
LOG: redirecting log output to logging collector process
HINT: Future log output will appear in directory "pg_log".
Done.
ALTER NODE
pgxc_pool_reload
------------------
t
(1 row)
- Enfin le dernier concernera le nœud de données.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
PGXC add datanode master datanode1 xxx.yyy.zzz.215 20008 20012 /home/postgres/pgxc/dn1_master none none none
...
Actual Command: ssh postgres@xxx.yyy.zzz.215 "( pg_ctl stop -w -Z restoremode -D /home/postgres/pgxc/dn1_master ) > /tmp/s-virtualmachine10-lias_STDOUT_8445_9 2>&1" < /dev/null > /dev/null 2>&1
Bring remote stdout: scp postgres@xxx.yyy.zzz.215:/tmp/s-virtualmachine10-lias_STDOUT_8445_9 /tmp/STDOUT_8445_10 > /dev/null 2>&1
Starting datanode master datanode1.
LOG: redirecting log output to logging collector process
HINT: Future log output will appear in directory "pg_log".
Done.
CREATE NODE
pgxc_pool_reload
------------------
t
(1 row)
EXECUTE DIRECT
pgxc_pool_reload
------------------
t
(1 row)
- Pour s'assurer que notre cluster fonctionne correctement, vous pouvez exécuter la commande suivante.
2.
3.
4.
PGXC monitor all
Running: gtm master
Running: coordinator master coord1
Running: datanode master datanode1
V. Utilisation et première interrogation▲
- Sur le nœud 1, exécuter la commande suivante pour créer une base de données test dans le cluster.
2.
$ pgxc_ctl Createdb test
Selected coord1.
- Utiliser l'outil psql pour se connecter sur le nœud coordinateur (nœud 2).
$ psql -h xxx.yyy.zzz.214 -p 20004 test
- Créer une table hashed qui sera distribuée entre les nœuds du cluster selon un hash de la colonne id.
2.
3.
4.
test=# create table hashed (id int, surname TEXT) DISTRIBUTE BY HASH(id);
CREATE TABLE
test=# insert into hashed VALUES (1, 'test');
INSERT 0 1
- Exécuter la commande suivante pour obtenir les informations de la table. Vous remarquerez sur la dernière ligne une information qui permet de connaître le nœud où est stockée cette table.
2.
3.
4.
5.
6.
7.
8.
test=# \d+ hashed
Table "public.hashed"
Column | Type | Modifiers | Storage | Stats target | Description
---------+---------+-----------+----------+--------------+-------------
id | integer | | plain | |
surname | text | | extended | |
Distribute By: HASH(id)
Location Nodes: ALL DATANODES
- Exécuter la commande suivante pour lister les instances de cette table.
2.
3.
4.
5.
test=# select * from hashed;
id | surname
----+---------
1 | test
(1 row)
Postgres-XL supporte l'importation de bases de données existantes. Les commandes qui ne sont pas reconnues seront ignorées à l'instar des Triggers par exemple. À l'inverse, il est également possible de faire une sauvegarde de toutes les données des nœuds de données (Data Node) et des coordinateurs. Toutes les informations liées à la sauvegarde et la restauration peuvent être trouvées sur le site officiel.
VI. Réplication de données et problématique de tolérance aux pannes▲
Nous allons nous intéresser dans cette section à décrire comment ajouter de nouveaux nœuds de données et nous montrerons comment distribuer les données sur ces nouveaux nœuds. Nous aborderons en dernière sous-section les problèmes de tolérance aux pannes lorsqu'un nœud est inaccessible.
VI-A. Ajout d'un nœud de type datanode▲
- Pour l'instant le cluster ne comporte qu'un seul nœud de données. Nous allons en ajouter un nouveau sans perturber le fonctionnement du cluster ou les données déjà enregistrées.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
PGXC add datanode master datanode2 xxx.yyy.zzz.216 20009 20013 /home/postgres/pgxc/dn2_master none none none
...
CREATE NODE
pgxc_pool_reload
------------------
t
(1 row)
EXECUTE DIRECT
pgxc_pool_reload
------------------
t
(1 row)
EXECUTE DIRECT
pgxc_pool_reload
------------------
t
(1 row)
- Notons que l'ajout d'un autre nœud de données ne fait pas automatiquement redistribuer les données déjà insérées. Pour vérifier cela, veuillez vous reconnecter sur le nœud 2 depuis l'outil psql.
2.
3.
4.
5.
6.
7.
8.
9.
PGXC psql -h xxx.yyy.zzz.214 -p 20004 test
test=# \d+ hashed
Table "public.hashed"
Column | Type | Modifiers | Storage | Stats target | Description
---------+---------+-----------+----------+--------------+-------------
id | integer | | plain | |
surname | text | | extended | |
Distribute By: HASH(id)
Location Nodes: datanode1
- Pour redistribuer les données de la table hashed sur le nouveau nœud, il suffit d'exécuter la commande suivante.
2.
test=# ALTER TABLE hashed ADD NODE (datanode2);
ALTER TABLE
- Assurons-nous que les données de la table hashed ont été redistribuées sur le nouveau nœud de données.
2.
3.
4.
5.
6.
7.
8.
test=# \d+ hashed
Table "public.hashed"
Column | Type | Modifiers | Storage | Stats target | Description
---------+---------+-----------+----------+--------------+-------------
id | integer | | plain | |
surname | text | | extended | |
Distribute By: HASH(id)
Location Nodes: ALL DATANODES
VI-B. Ajout d'un nœud de données esclave▲
- Pour l'instant nous disposons de deux nœuds de données. Nous allons ajouter un nœud de données esclave au nœud de données 1. Toujours depuis le nœud GTM, exécuter la commande suivante.
2.
PGXC add datanode slave datanode1 xxx.yyy.zzz.217 40101 40111 /home/postgres/pgxc/dn1_slave none /home/postgres/pgxc/dn1_archlog.1
...
- Assurons-nous que notre cluster fonctionne correctement.
2.
3.
4.
5.
6.
PGXC monitor all
Running: gtm master
Running: coordinator master coord1
Running: datanode master datanode1
Running: datanode slave datanode1
Running: datanode master datanode2
- À noter qu'un nœud esclave fonctionne en réplication synchrone. Pour vérifier cela, exécuter la commande suivante depuis l'outil psql sur le nœud du coordinateur.
2.
3.
4.
5.
test=# EXECUTE DIRECT ON(datanode1) 'SELECT client_hostname, state, sync_state FROM pg_stat_replication';
client_hostname | state | sync_state
-----------------+-----------+------------
| streaming | sync
(1 row)
VI-C. Simulation d'une reprise sur panne▲
- Ajoutons des données dans la table hashed afin de valider cette réplication.
2.
test=# INSERT INTO hashed SELECT generate_series(1001,1100), 'foo';
INSERT 0 100
- Pour connaître la distribution des données en fonction des différents nœuds de données, exécuter la commande suivante.
2.
3.
4.
5.
6.
test=# SELECT p.node_host, p.node_name, count(*) FROM hashed h, pgxc_node p where h.xc_node_id = p.node_id GROUP BY p.node_name, p.node_host;
node_host | node_name | count
----------------+-----------+-------
xxx.yyy.zzz.215 | datanode1 | 53
xxx.yyy.zzz.216 | datanode2 | 48
(2 rows)
- Afin de tester la tolérance aux pannes et de voir l'intérêt du nœud de données esclave, nous proposons d'arrêter le nœud de données 1 en exécutant la commande suivante.
2.
3.
PGXC stop -m immediate datanode master datanode1
Stopping datanode master datanode1.
Done.
- L'exécution des requêtes sur le cluster est désormais impossible, car des données sont manquantes (53 instances ne sont plus disponibles). Pour vérifier cela, exécuter la ligne de commande suivante.
2.
3.
test=# SELECT p.node_host, p.node_name, count(*) FROM hashed h, pgxc_node p where h.xc_node_id = p.node_id GROUP BY p.node_name, p.node_host;
ERROR: Failed to get pooled connections
...
- Comme Postgres-XL ne supporte pas la reprise sur panne (fail over) automatique, il faut le traiter explicitement. Exécuter la commande suivante.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
PGXC failover datanode datanode1
Failover specified datanodes.
Failover the datanode datanode1.
...
ALTER NODE
pgxc_pool_reload
------------------
t
(1 row)
EXECUTE DIRECT
pgxc_pool_reload
------------------
t
(1 row)
EXECUTE DIRECT
pgxc_pool_reload
------------------
t
(1 row)
Done.
- Vérifions maintenant que la requête précédente fonctionne désormais correctement.
2.
3.
4.
5.
6.
test=# SELECT p.node_host, p.node_name, count(*) FROM hashed h, pgxc_node p where h.xc_node_id = p.node_id GROUP BY p.node_name, p.node_host;
node_host | node_name | count
----------------+-----------+-------
xxx.yyy.zzz.216 | datanode2 | 48
xxx.yyy.zzz.217 | datanode1 | 53
(2 rows)
- Le nœud de données esclave a pris maintenant la place du nœud de données maître. Ceci peut être confirmé à travers les résultats de la requête suivante.
2.
3.
4.
5.
6.
7.
test=# SELECT oid, * FROM pgxc_node;
oid | node_name | node_type | node_port | node_host | nodeis_primary | nodeis_preferred | node_id
-------+-----------+-----------+-----------+----------------+----------------+------------------+------------
11819 | coord1 | C | 20004 | xxx.yyy.zzz.214 | f | f | 1885696643
16400 | datanode2 | D | 20009 | xxx.yyy.zzz.216 | f | f | -905831925
16384 | datanode1 | D | 40101 | xxx.yyy.zzz.217 | f | f | 888802358
(3 rows)
- Il est à noter que le nœud de données 1 originel a été totalement supprimé du cluster. Il n'existe plus dans le fichier de configuration pgxc_ctl.conf. Une façon de le réutiliser s'il est disponible est de le définir à son tour esclave du nouveau nœud de données 1. Exécuter la ligne de commande suivante.
2.
3.
4.
add datanode slave datanode1 xxx.yyy.zzz.215 20008 20012 /home/postgres/pgxc/dn1_master none /home/postgres/pgxc/dn1_archlog.1
...
LOG: redirecting log output to logging collector process
HINT: Future log output will appear in directory "pg_log".
- Pour s'assurer que le cluster est dans l'état souhaité, exécuter la ligne de commande suivante.
2.
3.
4.
5.
6.
PGXC monitor all
Running: gtm master
Running: coordinator master coord1
Running: datanode master datanode1
Running: datanode slave datanode1
Running: datanode master datanode2
VII. Conclusion et perspectives▲
Nous avons vu à travers ce tutoriel l'installation de Postgres-XL, une version distribuée de la base de données PostgreSQL. Nous avons expérimenté sur un cluster de test contenant cinq nœuds.
Cette version propose des fonctionnalités intéressantes (distribution de données et requêtes distribuées notamment). Nous remarquons toutefois des désavantages dus par exemple à la reprise aux pannes où nous devions la gérer manuellement.
Au niveau des perspectives, il serait intéressant de vérifier pour Postgres-XL :
- la robustesse lors d'une montée en charge horizontale ;
- le fonctionnement sur une plus longue durée ;
- la mise en place d'un load balancing ;
- la tolérance aux pannes lors de la perte de plusieurs nœuds.
VIII. Remerciements▲
Nous tenons à remercier la société BIMEDIA qui a permis aux auteurs d'expérimenter la solution Postgres-XL. Nous tenons également à remercier Stéphane Jean pour ses nombreux conseils.
Enfin, nous tenons à remercier Claude Leloup pour la relecture orthographique de cet article et chrtophe pour sa relecture technique attentive et ses nombreuses bonnes pratiques.